On August 4th, 2025, Lighter tasked zkSecurity with auditing its Plonky2 circuits. The audit lasted three weeks with two consultants.
During the engagement, the team was granted access to the relevant parts of the Lighter codebase via a custom repository. Additionally, a whitepaper outlining various aspects of the protocol was also shared.
Scope
The scope of the audit included the following components:
- All top-level circuits in the Prover’s
circuit/src/ directory.
- All circuits in
circuit/src/types and circuit/src/transactions.
- The low-level circuit in
circuit/src/bigint/unsafe_big/mod.rs.
Summary and recommendations
Overall, we found the codebase to be well-structured and tested.
Unfortunately, both the documentation and the whitepaper were outdated and did not reflect the current state of the codebase.
Apart from the concrete findings listed at the end of this report, we have some strategic recommendations for keeping the codebase secure in the longer term:
- Document the state machine and valid transitions: The state machine of the rollup is quite complex, and there is a high number of possible transactions. It would be beneficial to write a clear specification of the valid state transitions, together with a description of the invariants that must be preserved during execution.
- Minimize code duplication: There are several instances of code duplication in the codebase, for example, different transactions that implement similar checks. Duplicated code is harder to maintain and can lead to inconsistencies long-term. We suggest refactoring the codebase to group similar checks into reusable gadgets.
- Document the usage of the fields and the objects in the transaction state: The account and order objects in the transaction state are used in different ways depending on the context. Additionally, these objects are used as both an input and an output of the transaction processing, which can be confusing and error-prone.
- Be careful about empty objects that hash to zero: Sparse Merkle trees are ubiquitous in the codebase. They are implemented with the common heuristic that an empty leaf hashes to zero. This allows for a standardized and efficient computation of the root for an empty tree of any depth for any data structure. However, if a leaf is considered empty only considering a subset of its fields, it can lead to non-determinism in reading a leaf from the current state, and important checks being skipped. We refer to our finding below for a concrete example of this issue.
Introduction
Lighter is an application-specific, EVM-compatible zk-rollup that implements a non-custodial exchange with a special focus on perpetual futures. Lighter’s layer 2 (L2) state transitions are verified and finalized on a layer 1 (L1) chain — currently, Ethereum. The L1 ensures that a batch of L2 state transitions is valid by verifying a corresponding zero-knowledge proof (ZKP).
The role of the ZKP is twofold: to prove that the batch of L2 transitions is valid and to interact with the L1 contracts to expose relevant information about the transition batch.
Some transitions require additional logic execution and policy enforcement on the L1.
Additionally, the rollup implements a censorship-prevention mechanism, ensuring that the sequencer cannot censor the inclusion of transactions in the L2 state for too long; otherwise, the L1 contracts will stop normal operation and switch to a “desert mode,” where users can withdraw their funds directly from the contracts.
There are three main components that make up the Lighter protocol: the Sequencer, the Prover, and the Smart Contracts.
The Sequencer is the primary interface for users: it organizes transactions into structured blocks and commits these blocks to the L1 for immutable storage.
The Prover takes the current state of the rollup and a batch of user transactions as inputs, processing them to generate a proof of execution.
These proofs are used to verify the correctness of the new state, ensuring that it is the result of a correct execution of the specified transactions.
Lastly, the Smart Contracts act as a settlement layer for the rollup, maintaining the integrity of the system by storing block and state root information and by verifying the block-execution proofs to correctly update the state.
A detailed introduction to Lighter’s protocol has already been created during our previous audit engagement, we refer the reader to this report.
Since there have been some changes (most notably, the circuits have been migrated from Gnark to Plonky2), we also give an overview of the main components of the circuits below.
Overview of the circuits
The current audit was focused on Lighter’s Prover component, which implements the verifiable matching and liquidation engines that generate block-execution proofs through its arithmetic circuits.
For each block, the Prover generates a proof for the execution of a set of transactions.
Each block encompasses a pre-execution phase and several execution cycles.
Each transaction is either executed in a single execution cycle or unrolled into multiple execution cycles.
Once all the cycles are executed, the arithmetic circuits compute a block commitment, which is the composite hash of the old and new state roots, as well as the block and transaction data.
The Prover then generates a proof for the execution of the corresponding block, where the block commitment is the public input used for proof verification.
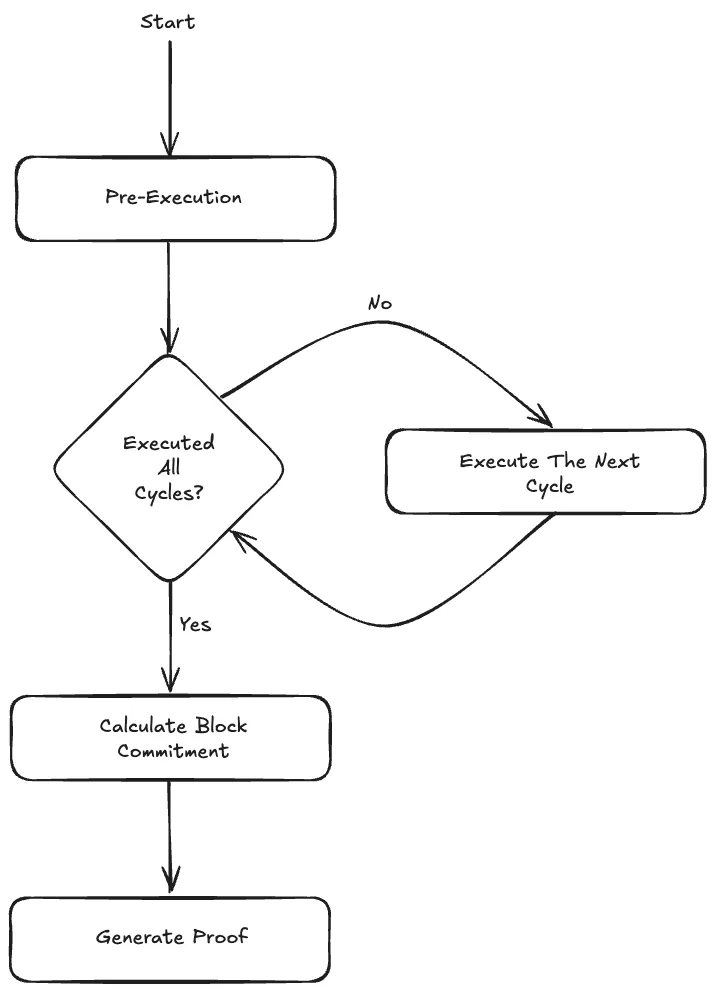
Special emphasis was placed on the following circuits:
BlockPreExecutionCircuit. Handles block-level pre-execution operations like funding rate calculations and oracle-price processing.
BlockTxCircuit. Processes a batch of transactions within a block (at the time of writing, batches of six transactions).
BlockTxChainCircuit. Aggregation layer that implements recursive proof composition of transaction batches. In particular, it performs “IVC-style” aggregation, recursively verifying a proof for BlockTxCircuit for the block, and verifying a proof for BlockTxChainCircuit for the batch. The resulting proof is a BlockTxChain proof for the block. Notice that this design allows the block to contain an arbitrary number of transactions.
BlockCircuit. Top-level circuit that recursively verifies a pre-execution and transaction-processing proofs into a block proof.
The “block-circuit hierarchy” can be depicted as follows:
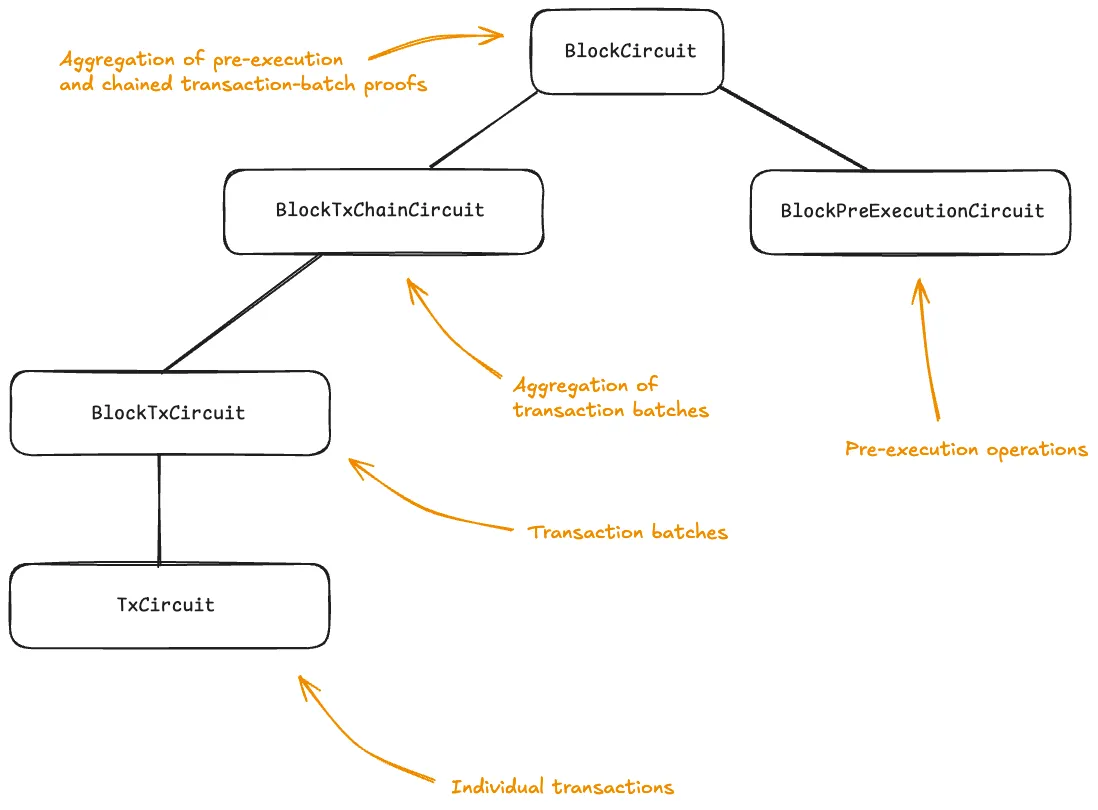
Block Circuits
The BlockPreExecutionCircuit is responsible for processing block-level operations that occur before individual transaction execution. It maintains important economic parameters of Lighter’s trading platform through three primary mechanisms:
- Oracle price updates
- Premium calculations
- Funding rate calculations
Since perpetual futures do not have an expiry date, the price of a perpetual-future contract can drift away from the underlying asset’s spot price if left unchecked. To fix this, Lighter implements a periodic funding mechanism: a fee that’s periodically exchanged between longs and shorts to maintain price stability and avoid significant deviations of perpetual-future prices from the spot price. When the funding rate is positive, users with long positions pay a funding fee to users with short positions. When the funding rate is negative, users with short positions pay a fee to users with long positions. These payments are fully peer-to-peer with no fees taken by the exchange.
To determine the index price (which is equivalent to the spot price), Lighter currently uses a combination of oracles, with Stork as their main oracle provider.
One crucial quantity for the computation is the 1-hour premium, which is computed as follows: every minute, Lighter calculates the premium of each market, i.e., the differentiation of the mark price from the index price via:
At the end of each hour, the 1-hour premium is then calculated as the time-weighted average of the 60 premiums calculated over the last hour.
Additionally, each market has a fixed interest rate component that accounts for the difference in interest rates of the base and quote currencies. Together with the aforementioned 1-hour premium, the funding rate is then calculated via:
Notice that division by 8 ensures that funding payments for the premium are distributed over 8 hours, aligning Lighter with the funding approach of most centralized perpetual exchanges. The funding round payment for account and market is then calculated as follows:
While pre-execution handles block-level economic parameters, the BlockTxCircuit handles individual transactions using that economic context, i.e., it performs the actual trading operations.
The circuit is responsible for processing a configurable batch of (currently 6) transactions with each transaction receiving the current state and producing an updated state that becomes the input for the next transaction.
The core part of this process is the following loop in the circuit’s define_tx_loop function:
// For each transaction, the circuit calls the transaction's "define" method,
// which processes the transaction and returns the updated state
for (index, tx) in self.target.txs.iter_mut().enumerate() {
let (
tx_priority_operations_pub_data,
priority_operations_pub_data_exists,
tx_on_chain_operations_pub_data,
on_chain_pub_data_exists,
register_stack_after,
all_market_details_after,
account_tree_root_after,
account_metadata_tree_root_after,
market_tree_root_after,
) = tx.define(
index,
chain_id,
&mut self.builder,
self.target.created_at,
¤t_register_stack,
¤t_all_market_details,
current_account_tree_root,
current_account_metadata_tree_root,
current_market_tree_root,
);
current_register_stack = register_stack_after;
current_all_market_details = all_market_details_after;
current_account_tree_root = account_tree_root_after;
current_account_metadata_tree_root = account_metadata_tree_root_after;
current_market_tree_root = market_tree_root_after;
on_chain_operations_count = self
.builder
.add(on_chain_operations_count, on_chain_pub_data_exists.target);
on_chain_operations_pub_data = self.builder.select_arr_u8(
on_chain_pub_data_exists,
&tx_on_chain_operations_pub_data,
&on_chain_operations_pub_data,
);
priority_operations_count = self.builder.add(
priority_operations_count,
priority_operations_pub_data_exists.target,
);
priority_operations_pub_data = self.builder.select_arr_u8(
priority_operations_pub_data_exists,
&tx_priority_operations_pub_data,
&priority_operations_pub_data,
);
}
The batch proofs generated by this circuit are subsequently aggregated through the BlockTxChainCircuit. This circuit is a recursive proof aggregation circuit that is responsible for combining the batch proofs from BlockTxCircuit into a single aggregated proof that can subsequently be combined with the proof from the pre-execution circuit. The cyclic proof composition allows the Lighter prover to process an arbitrary number of batches while maintaining a constant proof size for the whole block.
On a high level, the aggregation flow of the circuit can be thought of as follows:
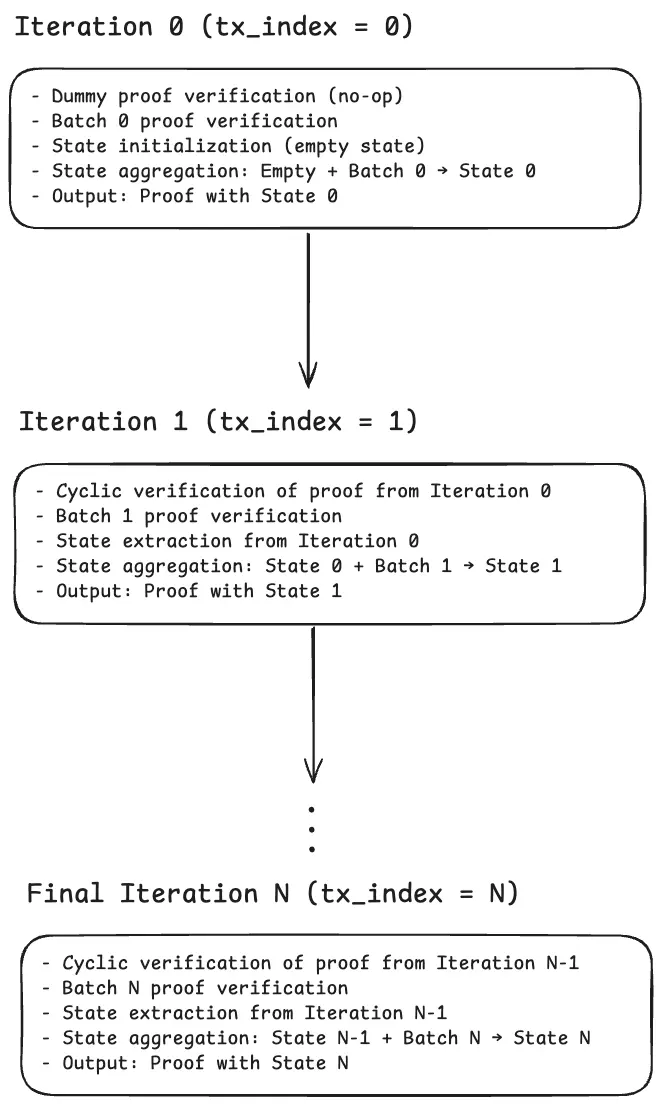
The BlockCircuit serves as the final step in the block processing pipeline. After the BlockPreExecutionCircuit has handled the economic parameters (funding rates, premiums, oracle prices) and the BlockTxChainCircuit has aggregated all the batch proofs, the BlockCircuit takes the outputs of these two circuits and combines them into a single block proof.
Rollup State Tree
The state tree is a combination of multiple Merkle and sparse Merkle trees, which are used to store all the information about the rollup state.
The state tree hash is a cryptographic hash that uniquely represents the entire state of the rollup at a given point in time.
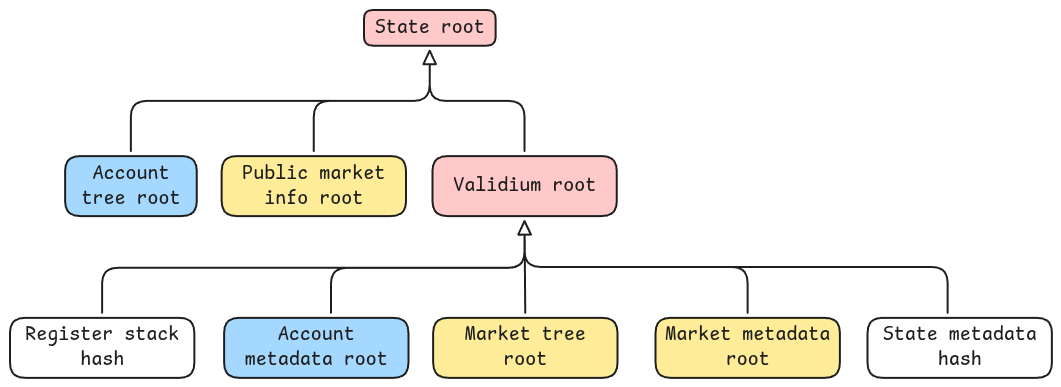
We briefly describe the main components of the state tree.
Account information is stored in two separate sparse Merkle trees, rooted respectively in the account tree root and the account metadata tree root.
- For each account, relevant information is stored in the account tree, such as the collateral, the positions, and the public pool shares owned by the account.
- The account metadata tree stores additional information about the account, such as the number of orders, the DMS switch time, the API keys tree root, and the account order tree root.
Worthy of note is the account order tree, which is a Merkle tree that stores all the orders for a given account.
Orders are stored in two positions, named index0 and index1, which are computed using two different strategies.
index0 is computed using the first 8 bits as the market index and the last ORDER_NONCE_BITS bits as the order nonce.index1 is computed using a hash of a client order ID of size CLIENT_ORDER_ID_BITS, which is provided by the user when creating the order. Notice that ORDER_NONCE_BITS is equal to CLIENT_ORDER_ID_BITS, so both indices are of the same size.
Both orders live in the same tree but in separate parts.
The account order index is computed first by choosing the 8-bit market index and then adding the order nonce.
account_order_index = (market_index + 1) * (1 << ORDER_NONCE_BITS) + order_nonce
The market index is incremented by one because market index 0 is reserved for client order IDs, ensuring that the two index spaces are disjoint.
For a description of the order book tree, we refer to the previous audit report, since the data structure is unchanged.
Transaction Processing
Transactions are the means by which the rollup state is modified.
The engine that checks the validity of transactions takes as input the current state tree of the rollup and a transaction and produces as output a new state tree.
Reading from the state is done by verifying Merkle proofs for the relevant objects involved in the current transaction, and writing to the state is done by updating the objects and recomputing the Merkle roots up to the state root.
Overview of Transaction Types
Transactions are divided into three main categories:
- Internal transactions: These are transactions that are enqueued by the sequencer automatically and are either “system” transactions used to execute the unrolled instructions or are sent by the sequencer when certain triggers are hit (e.g., a liquidation or a stop-loss order).
- L1 transactions: These are transactions that are sent by users on L1 and are enqueued in the priority queue. They are executed in the order they are enqueued, and a block can contain at most one L1 transaction.
- L2 transactions: These are transactions that are sent by users to the sequencer and are enqueued by the sequencer. A block can contain an arbitrary number of L2 transactions.
We now give an overview of all the transaction types.
Internal transactions
Order internal transactions:
- Internal cancel all orders: cancels all orders for a given account. This can be enqueued either because the account is in liquidation, or because the dead man switch should be triggered. This transaction pushes a
CANCEL_ALL instruction on the register stack.
- Internal cancel order: cancels a single order for a given account. This is the result of either a single cancel order instruction, or a “cancel all” instruction. If it is part of an unrolled “cancel all”, the register stack is modified to contain the remaining orders to cancel. If there are no more orders to cancel, the register stack is popped.
- Internal claim order: this transaction is used to continue the matching of a taker order that was partially matched in the previous cycle. The register stack is modified by the matching engine to contain the remaining size of the taker order to match, or it is popped if the order was fully matched in this cycle.
- Internal create order: this transaction is used to insert an order that was previously submitted. This can be either the result of a triggered order by price (e.g., stop-loss or take-profit), a triggered order by time (in TWAP orders), or a trigger of a child order (in OTO/OCO/OTOCO orders).
Risk management internal transactions:
- Internal liquidate position: this transaction is used to liquidate an account whose health is in “partial liquidation”. The transaction will try to improve the account’s health by inserting an immediate-or-cancel order at the “zero price”, which is the special price for which the ratio between the maintenance margin requirement and the account value stays the same after the trade.
- Internal deleverage: this transaction is used to perform a deleverage of an account that is in bankruptcy. The sequencer will select a counterparty account that has a position in the opposite direction, and will forcefully apply a trade between the two accounts. The deleverager account can be either an insurance fund, or a regular user selected from the automatic deleverage queue.
- Internal exit position: this transaction is enqueued when a market has expired, and it forces the account to exit its position at the latest price.
L1 transactions
Deposit and withdraw transactions:
- L1 Deposit: this transaction is used to deposit funds into a (possibly new) account. The accepted funds are added to the account’s collateral. The sequencer may accept fewer funds than are sent.
- L1 Withdraw: this transaction is used to withdraw funds from the L2 by an account. The requested funds are subtracted from the account’s collateral and posted on-chain as a “withdraw” operation.
Account and order management transactions:
- L1 Create Order: this transaction is used to create a new order for a given account. The transaction pushes an
INSERT_ORDER instruction on the register stack.
- L1 Cancel All Orders: this transaction is used to cancel all orders for a given account. This transaction pushes a
CANCEL_ALL instruction on the register stack.
- L1 Change Pubkey: this transaction is used to change one of the public keys (also known as API keys) of an account or to create a new one.
- L1 Burn Shares: this transaction is used to burn the pool shares of an account. The account receives its portion of the total pool value in exchange for burning the shares.
Market management transactions:
- L1 Create Market: this transaction is used to create a new market. This transaction can only be executed by the protocol’s governor, which is enforced by the L1 contracts.
- L1 Update Market: this transaction is used to update the parameters of a market. This transaction can also only be executed by the protocol’s governor.
L2 transactions
Funds-transferring transactions:
- L2 Transfer: this transaction is used to transfer funds between two accounts.
- L2 Withdraw: L2 version of the withdraw transaction.
Order transactions:
- L2 Create Order: L2 version of the create order transaction.
- L2 Create Grouped Orders: this transaction is used to create a group of orders that are linked together. The order group type can be either OCO, OTO, or OTOCO.
- L2 Modify Order: this transaction is used to modify an existing order.
- L2 Cancel Order: this transaction is used to cancel a single order for a given account.
- L2 Cancel All Orders: L2 version of the cancel all orders transaction.
Public pool transactions:
- L2 Create Public Pool: this transaction is used to create a new public pool account, which can be either an insurance fund or a public pool. The account that creates the pool becomes the operator of the pool, deposits some funds in the pool, and receives the initial operator shares.
- L2 Update Public Pool: this transaction is used to update the parameters of a public pool. Only the operator of the pool can execute this transaction.
- L2 Mint Shares: this transaction is used to mint new shares for a public pool. The account that executes the transaction deposits some funds in the pool and receives the corresponding shares.
- L2 Burn Shares: L2 version of the burn shares transaction.
Margin and leverage transactions:
- L2 Update Leverage: this transaction is used to update the leverage parameters of an account for a market: the account can change between cross-margin and isolated margin, and can also change the initial margin fraction.
- L2 Update Margin: this transaction is used to update the individual allocated margin for the account positions in the case of isolated margin. The user can either increase or decrease the allocated margin for a given market.
Account management transactions:
- L2 Change Pubkey: L2 version of the change pubkey transaction.
- L2 Create Sub-Account: this transaction is used to create a new sub-account for an existing account.
Transaction Loop and the Register Stack
The instruction register stack is a data structure that stores the current state of execution of the current transaction.
At the beginning of each block, in the pre-execution step, the register stack is ensured to contain an EXECUTE_TRANSACTION instruction in its head.
The EXECUTE_TRANSACTION instruction is a special instruction type that signals to the rollup engine that all previous pending execution instructions have been completed and that a new transaction can be executed.
// Register stack should be in Execute Mode when pre-execution is in progress
let execute_transaction = self.builder.constant_from_u8(EXECUTE_TRANSACTION);
let is_register_instruction_type_execute = self.builder.is_equal(
self.target.register_stack_before[0].instruction_type,
execute_transaction,
);
// ...
self.builder.conditional_assert_true(is_pre_block_execution, is_register_instruction_type_execute);
The instruction register stack is an array of BaseRegisterInfoTarget objects.
Instructions that are pushed on the stack need to be executed before processing the next transaction, while instructions that are popped from the stack are considered completed.
The engine enforces that, if the stack is not empty, only the correct transaction type can be executed.
For example, if the top instruction on the stack is an INSERT_ORDER instruction, that means that a partial matching is in progress, and the next enqueued transaction must be an internal claim order transaction to continue the matching of the order.
Each BaseRegisterInfoTarget object is represented in the following structure.
pub struct BaseRegisterInfoTarget {
pub instruction_type: Target,
pub market_index: Target,
pub account_index: Target,
pub pending_size: Target,
pub pending_order_index: Target,
pub pending_client_order_index: Target,
pub pending_initial_size: Target,
pub pending_price: Target,
pub pending_nonce: Target,
pub pending_is_ask: BoolTarget,
pub pending_type: Target,
pub pending_time_in_force: Target,
pub pending_reduce_only: Target,
pub pending_expiry: Target,
pub generic_field_0: Target,
pub pending_trigger_price: Target,
pub pending_trigger_status: Target,
pub pending_to_trigger_order_index0: Target,
pub pending_to_trigger_order_index1: Target,
pub pending_to_cancel_order_index0: Target,
}
We briefly describe some of the most interesting fields of the instruction register.
- The
instruction_type field is used to determine the type of instruction being processed. In particular:
EXECUTE_TRANSACTION is used to indicate that no more instructions are to be processed and the next transaction can be whatever (L1/L2/internal).INSERT_ORDER is used to insert a new order into the order book.CANCEL_ALL_ACCOUNT_ORDERS, CANCEL_SINGLE_ACCOUNT_ORDER, CANCEL_POSITION_TIED_ACCOUNT_ORDERS, CANCEL_ALL_CROSS_MARGIN_ORDERS, and CANCEL_ALL_ISOLATED_MARGIN_ORDERS are used to cancel orders.TRIGGER_CHILD_ORDER is used to trigger a child order in an OTO order.
- The
pending_size field represents a generic execution amount left to process during instruction unrolling, with different meanings per instruction type.
- For
INSERT_ORDER instructions, it represents the remaining order size/quantity in base units.
- For
CANCEL_ALL instructions, it represents the count of orders still to cancel.
- The
generic_field_0 field is a generic field that is used to store the slippage accumulator for market orders during matching.
Matching Engine
The matching engine receives as input multiple objects, which are stored in the tx_state object.
The head of the register stack contains information about the taker order to be matched or inserted in the book. Notice that each match cycle only matches a taker order with at most one maker order, so if the match is partial, the remaining size of the taker order is left in the register stack as an INSERT_ORDER instruction, and the sequencer will subsequently sequence an “internal claim order” transaction to continue matching the taker order.
There are then the order and the account order objects, which are used for different purposes in the engine.
Initial matching engine setup.
Throughout the implementation, there are four main boolean flags that are used to control the effect of the matching engine:
update_status_flags: this flag acts as a general switch to enable or disable subsequent updates to the matching engine logic. It can be thought of as some sort of “unrolled early return”; that is, once it is set to false, all subsequent logic of the matching engine is disabled. It is worth noting that this flag is initially set to tx_state.matching_engine_flag, which is a flag that is set to true by transactions that require the activation of the matching engine. By default, it is set to false for all transactions.cancel_taker_order: this flag is set to true if the taker order should be cancelled after the matching process. This is done by just executing a pop from the instruction stack.cancel_maker_order: this flag is set to true if the maker order should be cancelled after the matching process, for example, because it has been fully matched by the taker order or because it has expired.insert_taker_order: this flag is set to true if the taker order should be inserted into the state after the matching process.
First, if the pending order trigger status is not NA, that means that the order has to be inserted into the pending order tree, and subsequent matching logic is disabled.
If the order is a “reduce only” order, then the direction of the order must be opposite to the position direction. That is, for an ask order, the overall position must be long, and for a bid order, the overall position must be short. If this is not the case, then the order is cancelled.
The order field in the tx_state contains an order index that depends on the context:
- if there is a matching order, then it is the maker order index
- if there is no matching order, then it is enforced to be the taker order index
In either case, the order index is used to compute if this is the best match in the order book, using a price-priority mechanism, as described in the next section.
Ensuring the best match in the order book.
The matching engine uses the get_quote function to get the size and quote of the orders with higher priority than the one currently being matched.
The output of this function is enforced to be zero, which enforces that the matched order is the best order in the book.
The mechanism is as follows: the function walks through the path for the current order, starting from the leaf order.
For each internal node, it computes the difference between the current size sum and the child node. This quantity corresponds to the size of the orders in the “sibling subtree” with respect to the child node.
Now, there are two scenarios, depending on whether the current child in the path is a left or right child:
- If the sibling subtree contains orders with higher priority than the current order, then the size of the orders in the sibling subtree is added to the accumulator.
- Otherwise, it is ignored, as the orders in the sibling subtree have a lower priority than the current order.
At the end, the accumulator contains the size of the orders with higher priority than the current order, and it is enforced to be zero.
We refer to the previous audit report for more details on how to compute the size and quote of the orders with higher priority.
We note that this computation works with either a matching order index or the taker order index: in either case, the returned quantity will be the amount of the orders that could have matched the current order, giving a better price priority than the current match.
Handling of self-trade orders.
Self-trade orders are orders that match with an order from the same account.
In this case, most of the logic is skipped, since a self-trade does not change positions. The only way a self-trade can fail is if the maker order has expired or if the pending order is a post-only order.
Slippage logic for market orders
On market orders, the user can specify an execution price, which is stored in the pending_price field of the register.
The matching engine has to guarantee that the average execution price of the order is not worse than the specified price.
To do so, the engine keeps track of the current slippage of the order in the generic_field_0 field of the register.
This field is initially set to zero and keeps track of the current slippage amount, which is the price difference in favor of the market order, weighted by the size of the executed orders so far.
To compute how much size can be safely executed without incurring too much slippage, the engine computes the integer division generic_field_0 / price_diff, where price_diff is the difference between the matched price and the price of the maker order, signed according to the direction of the order.
At the end of the matching process, if there has been a slippage in the matching, this field is updated accordingly.
To explain the mechanism, we consider the following example, which was provided by the Lighter team.
Suppose in the book there are two orders:
- Ask order of size 10 at price 100
- Ask order of size 10 at price 120
The user submits a bid market order of size 20 at price 105.
The matching engine will first match the first ask order of size 10 at price 100. In this case, no slippage is incurred because the price of the market order is better than the price of the maker order.
The generic_field_0 is updated to .
Then, the second ask order of size 10 at price 120 is matched. In this case, there is slippage because the price of the market order is worse than the price of the maker order.
However, since we matched 10 units at price 100 before, we can still execute a partial match of the market order without making the average execution price worse than the specified price.
In this second match, the price difference is 15, and the size of the executed order is computed as .
The average execution price is computed as
which is better than the specified price of 105 for a bid market order, so the overall execution is valid.
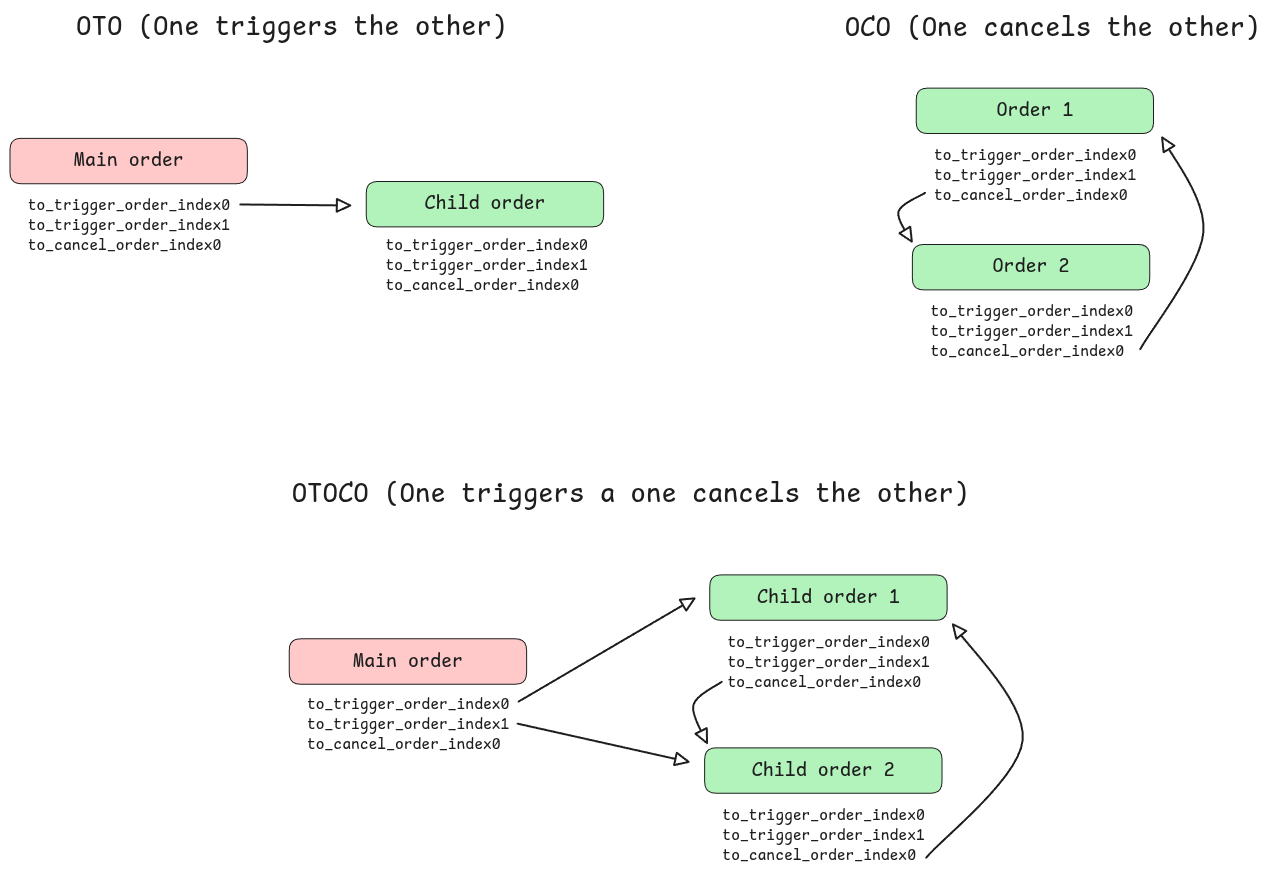
Order Groups
Order groups are a set of orders that are linked together: they can be either OCO, OTO, or OTOCO.
- OTO (One triggers the other): whenever the main order is filled, the child order is triggered and inserted. The main order can be either a limit or market order, while the child order must be a conditional order (e.g., stop-loss or take-profit).
- OCO (One cancels the other): whenever one of the two orders is triggered and inserted, the other is cancelled. In this case, both orders have to be conditional orders, and they must be opposite in direction (i.e., one is a stop-loss and the other is a take-profit).
- OTOCO (One triggers the other, one cancels the other): this is a combination of OTO and OCO orders. Whenever the main order is filled, two other orders are triggered and inserted, and they are linked together in an OCO group. This is used to simultaneously set a stop-loss and a take-profit order after entering a position.
In the circuits, order groups are handled using three index pointers in the order’s structure. The pending_to_trigger_order_index0 and pending_to_trigger_order_index1 fields are used to store the child orders that will be triggered when the current order is filled. The pending_to_cancel_order_index0 field is used to store the order that will be cancelled by the current order.
The pointer structure enforced by the “L2 Create Grouped Orders” transaction is depicted below.
Below are listed the findings found during the engagement. High severity findings can be seen as
so-called
"priority 0" issues that need fixing (potentially urgently). Medium severity findings are most often
serious
findings that have less impact (or are harder to exploit) than high-severity findings. Low severity
findings
are most often exploitable in contrived scenarios, if at all, but still warrant reflection. Findings
marked
as informational are general comments that did not fit any of the other criteria.